
收集和处理 INMET-BDMEP 气候数据(气候.收集.数据.BDMEP.INMET...)
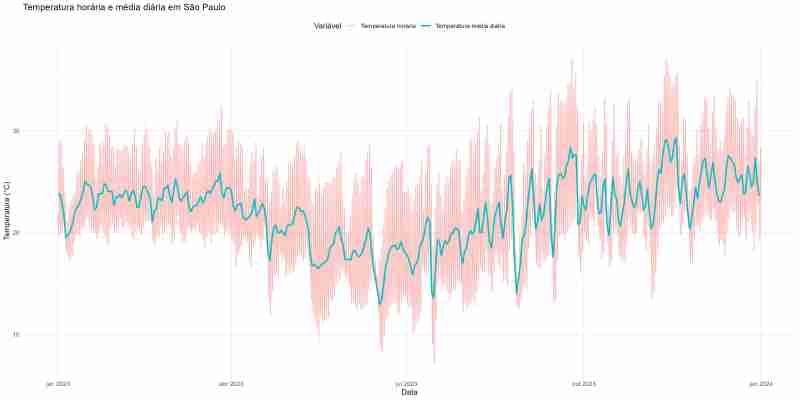
气候数据在多个领域发挥着至关重要的作用,有助于影响农业、城市规划和自然资源管理等领域的研究和预测。 国家气象研究所(inmet)每月在其网站上提供气象数据库(bdmep)。该数据库包含分布在巴西各地...
python怎么爬虫子(爬虫.python...)

python凭借其丰富的库和语法灵活性,是网络爬取的理想选择。爬虫步骤:1. 安装库:requests、beautifulsoup、lxml;2. 发送请求;3. 解析响应;4. 提取数据。最佳实践:...
爬虫python怎么用(爬虫.python...)

python 爬虫是一种利用 python 自动化从网站提取数据的工具。步骤如下:安装 bs4、requests、lxml 库。使用 requests 库连接到目标网站。使用 bs4 库解析 html...
python怎么做爬虫(爬虫.怎么做.python...)

爬虫是一种自动化程序,用于从互联网上提取和存储数据。python 是进行网络爬取的理想语言,因为它具有丰富的开源库,易于学习,可扩展、可维护,并且支持多线程和并发。构建 python 爬虫包括:安装必...
怎么提高python爬虫技术(爬虫.提高.技术.python...)

通过掌握 python 基础、http/https 协议和爬虫库,以及通过实践、处理挑战和获取进阶技巧,可以有效提升 python 爬虫技术。 如何提高 Python 爬虫技术 掌握基础知识 精通...
python怎么反爬虫(爬虫.python...)
python 提供多种反爬虫技术来阻止网络爬虫抓取数据:使用 robots.txt 阻止访问:通过创建 robots.txt 文件并指定 disallow 规则。使用 http 标头指示爬虫行为:如...
怎么用python爬虫(爬虫.python...)

如何使用 python 爬虫?安装请求、beautifulsoup 和 lxml 库。发送 http 请求获取网站 html 内容,解析 html 提取数据。存储或处理提取的数据,注意遵守网站使用条款...
python爬虫网页怎么抓(爬虫.网页.python...)

python 爬虫入门:通过安装 requests 和 beautifulsoup 库,发送 http 请求获取网页内容,利用 beautifulsoup 解析 html 文档,提取所需数据(如标题、...
python爬虫应该怎么学(爬虫.python...)

学习 python 爬虫的方法包括:掌握 python 基础熟悉 html 和 css学习 selenium使用 beautifulsoup了解 requests 库练习项目深入研究爬虫框架 Pyt...
Python怎么写爬虫代码(爬虫.代码.Python...)

python爬虫代码编写指南:导入库:使用requestsimport bs4等库进行数据获取和解析。发出http请求:通过requests库的get()方法获取网页内容。解析html响应:利用bs4...